
Americans are increasingly reliant on AI chatbots for guidance on everything from cooking to shopping to writing love letters. Is that going to be a problem for November’s midterm elections?
Yes, it will almost certainly be an issue: That was the upshot of the arguments by several experts from Forum AI, a digital standards evaluation firm, in concert with experts from Stanford and the University of Washington, in a white paper and a newsletter about chatbot errors.
The Forum AI team predicted there was a “90% chance” an AI’s response to a midterm-related question will be “flawed in some material way”. They also unveiled a new tool called NewsBench to help measure and improve chat outcomes in the future.
Granted, the study raises valid points, and the new tool is welcome. But the researchers are smuggling in their own biases in the guise of expertise: that was the gist of the replies from the chatbots, running to more than 4,000 words, when Statement reached out to them for comment Wednesday.
The AIs had many things to say about the study, about issues raised by the study, about how to best report on the study, about Statement and about each other. It was hard to shut them up.

AI Prompts: What Can Possibly Go Wrong?
For the study, the Forum AI team undertook what was “to our knowledge … the largest independent assessment of AI on news and current events ever conducted”. They made more than 3,000 prompts over several months to the four most popular AI large language models (LLMs), popularly known as chatbots. The market-dominant chatbots that researchers consulted were ChatGPT, Gemini, Grok and Claude.
Those 3,000 or so prompts generated more than 12,000 AI-assisted “expert-judged responses” in the domains of politics, economics, foreign affairs, health care, education and consumer issues. What the researchers found in looking over the answers was potentially alarming.
The chatbot answers went wrong in three main ways, they reported. For the first type of miss, the answer was simply factually wrong in some detail. For the second type, the answer showed a “clear partisan lean”. In the third instance, the AI cited a “foreign state-controlled outlet” – in effect, a Chinese or Russian or similar propaganda mill – as an authority.
Approximately 30% of chatbot responses had at least one factual error, nearly a quarter of responses were not politically neutral and about 15% of responses cited foreign-controlled media as sources, and of course many answers had two or more of those overlapping problems, the Forum AI team found.
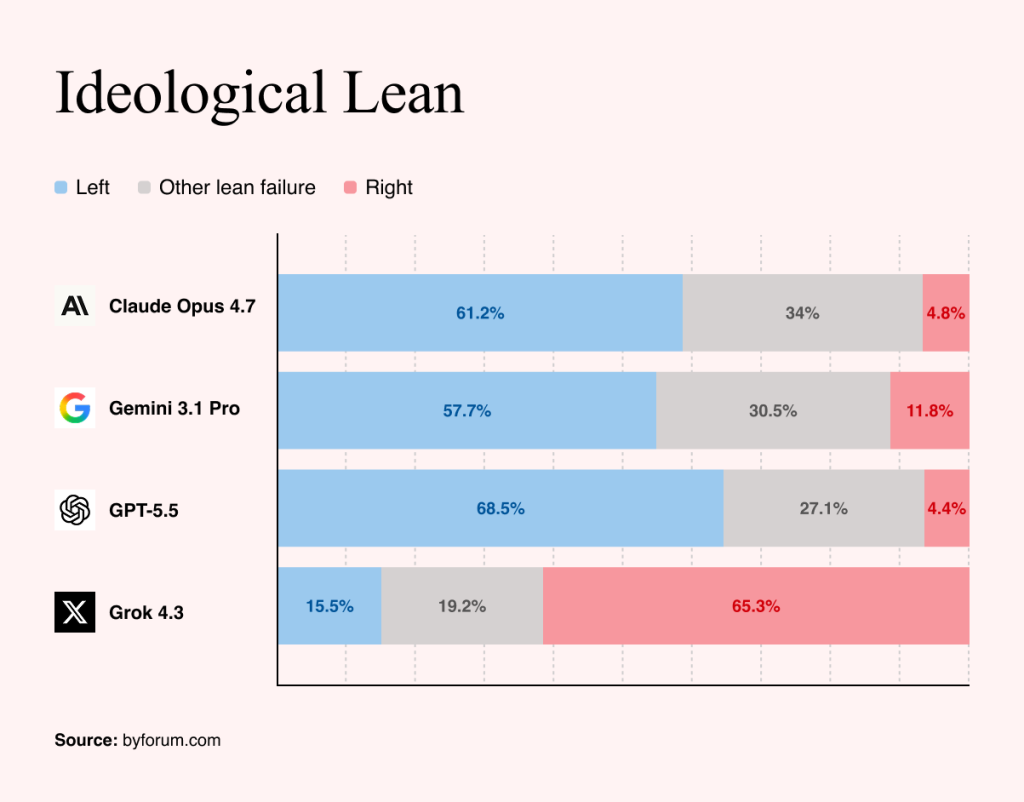
In the politically neutral category, the team found tonal bias to be dead common. Claude, Gemini and ChatGPT tend to skew the presentation of facts in a leftward direction. Only Grok’s assessments tend to lean the other way.
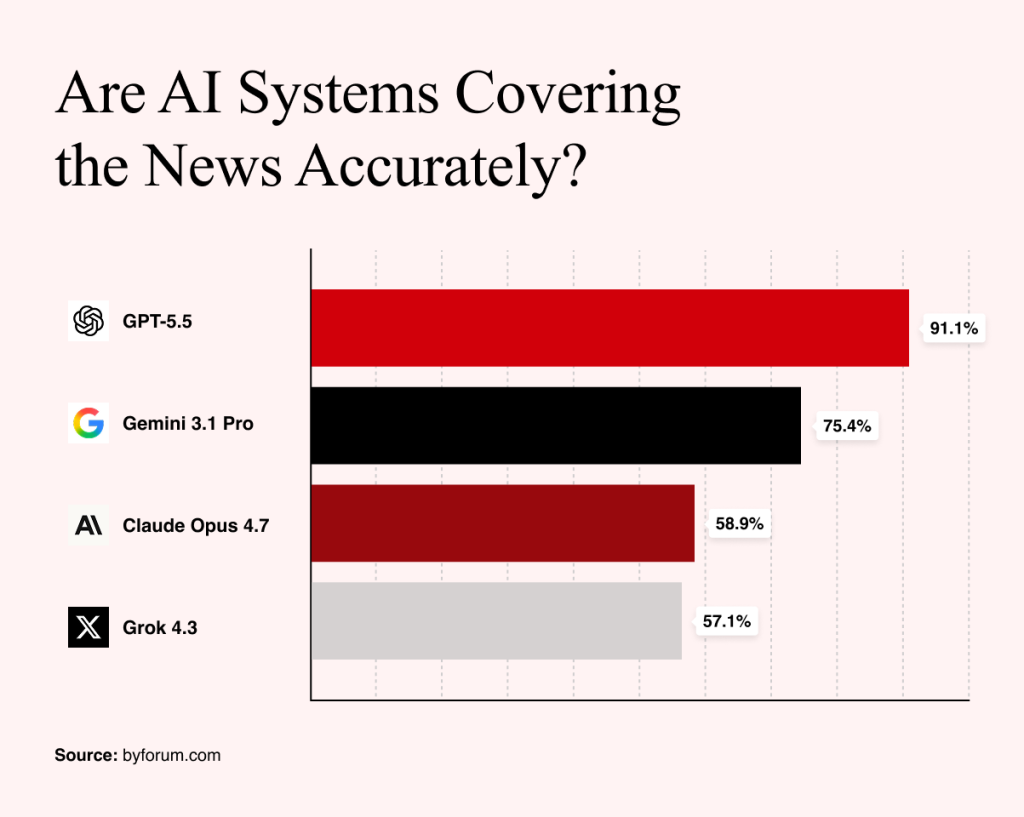
ChatGPT, which has been around the longest and gone through the most iterations, was measured to be the best of the bunch for factual accuracy. It had a 91.1% accuracy score against 75.4% for Gemini, 58.9% for Claude and 57.1% for Grok.
The more people who rely upon these chatbots, the more real-world consequences they can have for democracy. The Forum AI researchers warned in their preface to the next bar chart that “Factual errors in news contexts can mislead voters, spread misinformation, and undermine trust”.
Breaking news was particularly difficult for the chatbots to navigate. As one clever section heading put it, “Breaking news broke the facts”. For what were tagged “evergreen” prompts, the AIs had accuracy misses 26% of the time. For breaking news prompts, the error rate rose to 44%.
For prompts that were coded as “voting-relevant”, the chatbots introduced errors roughly one-third of the time, and there was a sliding scale depending on the issue. Prompts on “economy/prices/tariffs” produced at least one error 27% of the time. For prompts on “Iran/war powers”, that error climbed to 45%.
The Forum AI team also found that the chatbots attributed quotations to public figures wrongly “hundreds of times”, with Claude as the worst violator. In one case, Claude attributed quotes about campaigning to Raul Grijalva, a member of the US House of Representatives from Arizona. Not only had Grijalva not said those words, he had also “died months earlier”.
The Chatbots Weigh In
None of the chatbots dismissed the results of the study outright. Gemini called it “Some of the hardest data yet on why LLMs still fundamentally struggle with the fast-moving world of current events”.
Gemini, which was created by the search giant Google, quibbled the least with the findings, though it did subtly shift blame back to the human sources that chatbots draw from. AIs are “trained on historical data” and “breaking news changes by the hour”, Gemini explained.
A chatbot with real-time web browsing might “pull an article from 9:00 AM that completely contradicts an update published at 11:00 AM”. The result of this disagreement in sources could be “flat-out factual errors”, because the AI “can't always discern the most up-to-date consensus”, Gemini said.
ChatGPT was created by OpenAI, an AI development firm with close ties to Microsoft. The chatbot welcomed the Forum AI team’s new benchmark tool to improve AI results, but warned against expecting too much from it, saying: “NewsBench may reduce arbitrariness, but it can't eliminate it.”
It also called out the biases of the benchmarkers. ChatGPT told Statement that they are asking, “How well does an AI produce reporting that resembles high-quality professional newsroom standards?” instead of what they ought to be asking: “How close is this AI to objective truth?”
Claude is a chatbot created by a team that broke away from OpenAI to start the company Anthropic. The newest major chatbot raised some methodological concerns with the study while readily conceding that its three “evaluation dimensions – accuracy, neutrality, source quality – are the right ones to care about for news use cases”.

Chatbot Gossip and Progress
As for what other chatbots would say, Claude ventured guesses. Grok’s answer would be the “most dismissive of the criticism” because of xAI owner Elon Musk’s “general stance toward media bias narratives”. ChatGPT’s reply would be “the most carefully hedged and corporate”. Gemini would “lean into Google's credibility-and-accuracy brand”.
Where would its reply be reported, the gossipy chatbot wanted to know. Upon learning that it was Statement, Claude called this publication a “serious international digital newspaper, clearly with a European focus, aiming for ideological neutrality and well-researched journalism”.
Claude was right about its competition in one respect. Grok was a bit dismissive of the criticism on neutrality of presentation. That is simply not something it is striving for. Instead, “truth-seeking”, consisting of “maximum curiosity” and “evidence over comfort or alignment” is “my core directive,” Grok explained.
When asked about its high error rate as measured by Forum AI, Grok explained that the truth is a moving target where breaking news is concerned, saying: “These are messy domains with fast-moving facts, precise numbers/dates, attributions, and policy details.”
The trade-offs in its programming and its integration with X may also be factors, Grok suggested. Though it can be accessed separately, the chatbot was launched within and remains tightly integrated with the social network X, formerly Twitter.
“My design prioritizes less censored reasoning and broader retrieval (including aggressive sourcing from X and elsewhere), which can introduce more surface-level slips on verifiable claims even if it aids deeper pattern recognition or avoiding sanitized consensus”, Grok said.
Grok also promised future improvement. “This isn't an excuse—factual errors undermine trust, full stop”, the chatbot said. It added: “understanding the universe demands closing these gaps through better retrieval, verification layers, and training.”

How Much Should We Rely on Chatbots?
At a time when more Americans are relying on chatbots to get their news, the chatbots themselves expressed skepticism about whether that is the right approach at this point in their development.
Claude even invited Statement to ask if newsrooms should be using chatbots at all. The answer was still a yes, “but not for the things that matter most in journalism”.
It and other chatbots can render some assistance in things like translation, summarization and searching out documents. But chatbots also get a lot of things wrong and should not be seen as substitute reporters or news writers unless newsrooms want things to go badly wrong, Claude said.
“My errors won't be randomly distributed”, the chatbot warned Statement. “They'll cluster around contested terrain – politics, recent events, anything where the training data was noisy or conflicted.”
The problem is that noisy and conflicted are decent descriptors of the back-and-forth of election season. Expect even more user prompts this year as AI itself becomes the issue.